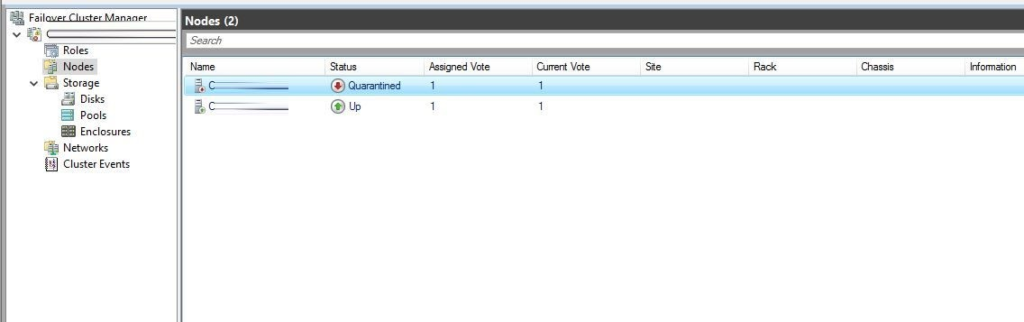
Cluster’a ekli olan bir node’un Quarantined mode’a düşmesi genellikle Windows Server Failover Clustering (WSFC) veya SQL Server Always On Availability Groups gibi kümeleme (clustering) ortamlarında görülür. Bir node karantina moduna geçtiğinde, cluster üyeliğinden geçici olarak çıkarılır ve belirli bir süre boyunca tekrar kümede up durumuna geçmez.
Bu duruma sebebiyet verecek bazı nedenleri ve olasılıklar vardır ;
Ağ Kopmaları ve İletişim Kesintileri
- Cluster node’ları birbirleriyle düzenli olarak “heartbeat” sinyali göndererek iletişim kurar.
- Eğer belirli bir süre boyunca düğüm diğer düğümlerle iletişim kuramazsa, network partitioning durumu oluşabilir.
- Sonuç olarak, WSFC node’u quarantine mode’a alır.
Sık Sık Node Ayrılmaları (Frequent Node Evictions)
- Bir node çok kısa aralıklarla kümeden ayrılıp tekrar bağlanıyorsa, kararsız bir düğüm olarak işaretlenir ve sistem güvenliği için karantinaya alınır.
- Örneğin, elektrik kesintileri, donanım sorunları veya sık sık yaşanan servis çakışmaları bu duruma sebep olabilir.
Sistem Kaynaklarının Yetersizliği (CPU, RAM, Disk I/O)
- Aşırı CPU kullanımı, yetersiz bellek veya disk gecikmeleri (I/O bottlenecks) cluster hizmetlerinin düzgün çalışmasını engelleyebilir.
- WSFC, performans sorunları yaşayan düğümleri kümeden ayırabilir.
Windows Update veya Yeniden Başlatmalar
- Beklenmedik veya plansız Windows güncellemeleri ve otomatik yeniden başlatmalar, cluster node’un düşmesine neden olabilir.
- Eğer bir düğüm çok kısa sürede birkaç kez restart edilirse karantina moduna alınabilir.
Heartbeat Timeout Değerleri Çok Düşükse
- Cluster’ın zaman aşımı eşikleri çok düşük ayarlanmışsa, geçici ağ dalgalanmaları bile düğümün karantinaya alınmasına neden olabilir.
Storage veya Network Bağlantı Problemleri
- Cluster Shared Volumes (CSV) erişim sorunları, disk bağlantı problemleri veya SAN/NAS kesintileri düğümün ayrılmasına yol açabilir.
- Son olarak Network katmanında oluşan aşırı gecikmeler de bu hataya neden olabilir.
Bu olasıkları ele aldıktan sonra birde bu durum oluştuktan sonra neler yapabiliriz node’u nasıl tekrar up duruma getirebiliriz ve sık sık tekrarlanmaması için nasıl değişiklikler yapabiliriz buna değinelim ;
Failover Cluster’da Quarantine Mode için beklenen 120 dakikalık süreyi beklemeden ilgili Node’u UP olarak düzenlemek isterseniz, öncelikle bir PowerShell penceresi açmanız gerekmektedir. Node’un karantina durumunu temizlemek ve tekrar aktif hale getirmek için kullanılması gereken sihirli PowerShell komut aşağıdaki gibidir 🙂
Start-ClusterNode –ClearQuarantine
Node’u ayağa kaldırdıktan sonra Cluster Quarantine ayarlarını aşağıdaki komutlar ile kontrol edelim
(Get-Cluster).QuarantineThreshold – bir node’un kaç kez cluster’dan ayrıldıktan sonra karantinaya alınacağını belirler.
(Get-Cluster).QuarantineDuration – bir node’un karantinada kalacağı süreyi (dakika cinsinden) belirler.
Bu ayarların default değerleri ;
(Get-Cluster).QuarantineThreshold → 3 (Bir düğüm 3 kez ayrılırsa karantinaya alınır.)(Get-Cluster).QuarantineDuration → 720 dakika (12 saat) (Düğüm 12 saat boyunca karantinada kalır.) dır.
Bu thresoldları güncellemek artırmak veya azaltmak için aşağıdaki komutları kullanabilirsiniz ;
(Get-Cluster).QuarantineThreshold = 5
(Get-Cluster).QuarantineDuration = 120
sonrasında değişiklikleri kontrol etmek için aşağıdaki komutları kullanabilirsiniz ;
(Get-Cluster).QuarantineThreshold
(Get-Cluster).QuarantineDuration
Umarım Faydalı Bir Yazı olmuştur. Bir sonraki yazıda görüşmek üzere 🙂